
Stručný úvod do ukazatelů
Ukazatele (anglicky pointers) rozhodně patří mezi prvky jazyku C, u kterých často dochází k nepochopení. Někdy to při práci s nimi může vypadat jako pěkná magie. Ve dnešním článku si vysvětlíme, co to ukazatele jsou a k čemu je můžeme využít.
Obsah článku:
Co je to proměnná
Ještě před tím, než se dostaneme k ukazatelům musíme mít jasno v tom, co je to proměnná.
Proměnná je pojmenované místo v paměti.
Ve článku o architektuře Arduina jsme si vysvětlili, jak to u Arduina funguje s paměťmi a že každá buňka v paměti má svoji adresu. A proměnná je takovýto „šuplík“ v paměti, který máme pojmenovaný, aby se nám s ním dobře pracovalo.

Každá proměnná má v C přiřazený svůj datový typ. Ten říká kompilátoru, jak má s danou proměnnou pracovat. O celočíselných datových typech a o tom, jak jsou uloženy v paměti, jsme psali například v tomto článku.
Datový typ říká mimo jiné i to, kolik bytů v paměti proměnná zabírá. Velikost datového typu se může lišit podle překladače i architektury. V kódu je možné ji zjistit pomocí operátoru sizeof. Když si spustíme následující kód, zjistíme, že například byte a int mají v Arduinu velikosti 1 a 2 byte (zkoušeno na desce Arduino Nano).
byte a;
int b;
void setup() {
Serial.begin(9600);
Serial.println(sizeof(a));
Serial.println(sizeof(b));
}
void loop() {}
Adresa proměnné
Ještě jednou si zopakujeme, že „proměnná je pojmenované místo v paměti„. Každé toto místo má svoji vlastní adresu. Adresa je v Arduinu organizovaná po bytech. Pokud chceme zjistit adresu proměnné, použijeme k tomu operátor &. Tomu se říká ampersand. Pokud si chcete jeho použití jednoduše zapamatovat, existuje poučka: „am-per-sand, ad-re-sa“.
Adresu proměnné int a; zjistíme výrazem &a;
Pojďme ampersand trochu prozkoumat. Podívejte se na následující kód.
int a = 257;
byte b = 5;
int c = 1024;
void prp(void *x) {
char s[20];
for(byte i = 0; i < 20; i++) {
s[i] = 0;
}
sprintf(s, "(%p) ", x);
Serial.print(s);
}
void setup() {
Serial.begin(9600);
Serial.print("a: ");
prp(&a);
Serial.println(sizeof(a));
Serial.print("b: ");
prp(&b);
Serial.println(sizeof(b));
Serial.print("c: ");
prp(&c);
Serial.println(sizeof(c));
}
void loop() {}
Podstatná je funkce prp. Co znamená void* si vysvětlíme za chvilku. U ní stačí vědět, že dostane adresu a vytiskne ji v závorkách na sériovou linku. Také si vypíšeme informace o velikosti proměnné. Měli bychom dostat podobný výpis, jako níže.
a: (0x103) 2
b: (0x102) 1
c: (0x100) 2
Proměnná a má adresu 0x103 a je dvoubytová (zabírá tedy i paměťovou buňku s adresou 0x104). Proměnná b má jeden byte a adresu 0x102. Proměnná c má opět dva byty a zabírá tudíž adresy 0x100 a 0x101. Naše situace je zakreslena na obrázku.

Co je to ten ukazatel?
Ukazatel je datový typ, který je určený k uchovávání adres. Poznáme ho podle toho, že je u něj při deklaraci hvězdička.
byte *x; int *y; float *z;
Tohle všechno (a mnohé další) jsou ukazatele. Čteme je postupně: ukazatel na hodnotu typu byte, ukazatel na hodnotu typu int atd. V proměnných typu ukazatel je tedy uložena adresa, na které čekáme, že bude uložena hodnota daného datového typu.
Poznámka: Mezeru lze psát před i za hvězdičkou. Zápisy byte* x; a byte *x; jsou ekvivalentní. Je ale lepší hvězdičky psát ke jménu proměnné (více viz komentáře k tomuto článku).
Jak je ukazatel velký?
Zkuste si spustit následující program. Jaký bude výstup? Proč tomu tak je?
byte *x;
int *y;
float *z;
void setup() {
Serial.begin(9600);
Serial.println(sizeof(x));
Serial.println(sizeof(y));
Serial.println(sizeof(z));
}
void loop() {}
Pro Arduino Nano (ale i UNO a další) budou mít všechny ukazatele velikost 2 byty. To je místo dostatečně velké na to, aby se do něj vešly všechny možné adresy, které čip podporuje. (Vzpomeňte si na článek o Arduino architektuře, kde jsme si ukázali, že mikrokontrolér ATmega328P má adresy od 0x0000 do 0x3FFF, což se spolehlivě vejde do dvou bytů.)
I proměnné typu ukazatel mají vlastní adresu. Lze tak vytvářet i pomerně děsivé konstrukce, jako ukazatel na ukazatel na byte, ukazatel na ukazatel na ukazatel na int a podobně, ale k výše než dvojitému ukazateli se většinou dostanete jen ve specifických případech, takže se jimi nemusíme moc zabývat. Zkusme se podívat na následující kód.
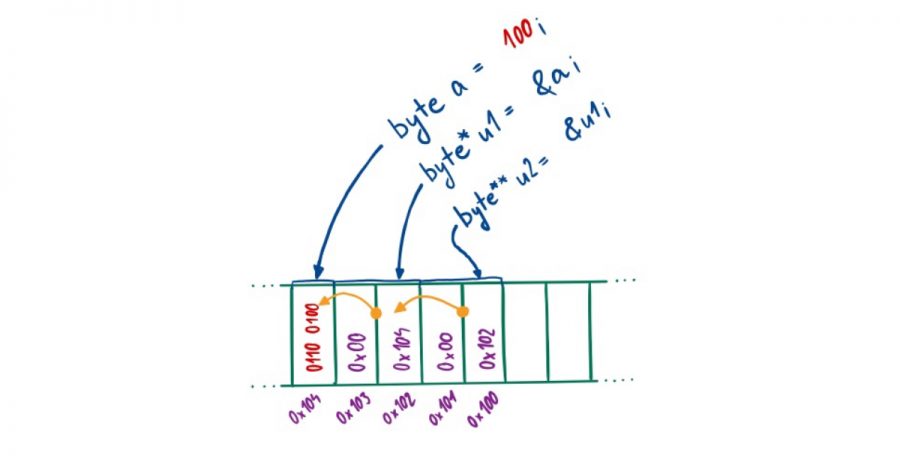
byte a = 100;
byte *u1 = &a;
byte **u2 = &u1;
void prp(void *x) {
char s[20];
for(byte i = 0; i < 20; i++) {
s[i] = 0;
}
sprintf(s, "(%p) ", x);
Serial.print(s);
}
void setup() {
Serial.begin(9600);
Serial.print("a: ");
prp(&a);
Serial.print(sizeof(a));
Serial.print(" ");
Serial.println(a);
Serial.print("u1: ");
prp(&u1);
Serial.print(sizeof(u1));
Serial.print(" 0x");
Serial.println((uint16_t)u1, HEX);
Serial.print("u2: ");
prp(&u2);
Serial.print(sizeof(u2));
Serial.print(" 0x");
Serial.println((uint16_t)u2, HEX);
}
void loop() {}
Oproti předchozímu kódu tento obsahuje navíc ještě výpis uložených hodnot. Po jeho spuštění bychom měli získat následující výpis:
a: (0x104) 1 100
u1: (0x102) 2 0x104
u2: (0x100) 2 0x102
Ten lze pro přehlednost přepsat do tabulky.
| Proměnná | Adresa | Velikost | Hodnota |
| a | 0x104 | 1 | 100 |
| u1 | 0x102 | 2 | 0x104 |
| u2 | 0x100 | 2 | 0x102 |

Získání hodnoty z adresy
Pokud chceme získat hodnotu v paměti, kam ukazatel ukazuje, použijeme k tomu operátor *. Zde nastává trochu matoucí situace, kdy hvězdičku používáme jak při deklaraci datového typu ukazatel, tak při získání hodnoty ukazatele. Na to si musíme dát pozor. Pokud bychom chtěli získat hodnotu z ukazatelů u1 a u2 z předchozího příkladu, použijeme následující zápis:
Serial.println(a); Serial.println(*u1); Serial.println(**u2);
Protože u2 je dvojitý ukazatel, musíme použít dvě hvězdičky, abychom se dostali až na hodnotu uloženou v a. Pokud bychom použili pouze jednu, dostaneme se na adresu uloženou v u1.
Kromě čtení hodnot je možné stejným způsobem do proměnných i zapisovat. Všechny tři následující výrazy zapisují v konečném důsledku do proměnné a.
a = 100; *u1 = 200; **u2 = 300;
K čemu je to dobré?
Jen tak pro nic za nic by ukazatele v jazyku C nebyly. K čemu je tedy využijeme? Velice často se například používají při práci s poli. Tuto část si necháme na článek, který se bude polím věnovat. Taky je využijeme při tvorbě různých složitějších paměťových struktur, jako jsou seznamy, stromy, a další. Tyto struktury mohou mít celkem zajímavé vlastnosti (v seřazených stromech lze rychle vyhledávat, …), ale jsou trochu neúsporné na paměť. A zrovna paměti máme v Arduinu celkem nedostatek, takže u něj většinou zmíněné struktury nevyužijeme. Rozhodně je ale využijeme při předávání dat do a z funkcí.
Způsoby předávání dat do funkce
Pokud se omezíme pouze na využívání parametrů funkce, máme dvě možnosti, jak hodnoty do funkce předat. Tyto způsoby se nazývají předávání hodnotou a předávání odkazem.
Předání hodnotou
Tento způsob jste jistě někdy použili. Ukážeme si ho na příkladu.
int secti(int a, int b) {
return a + b;
}
Při předávání parametrů hodnotou je hodnota parametu při zavolání funkce skutečně překopírována do paměti vyhrazené pro parametry funkce. Odkud ji může funkce číst a dále zpracovávat.
Předání odkazem
U předávání odkazem je situace trochu jiná. V tomto případě pomocí parametru říkáme „tady máš adresu, na které najdeš hodnoty, které potřebuješ“. Když předchozí funkci přepíšeme na předávání odkazem, bude vypadat následovně.
int secti(int *a, int *b) {
return *a + *b;
}
A použítí této funkce je následující.
int x = 10; int y = 20; int z = secti(&x, &y);
Předávání odkazem má ještě jednu výhodu. Protože víme adresu hodnot předávaných odkazem, můžeme je uvnitř funkce měnit a tato změna se projeví i vně funkce!
void vymen(int *a, int *b) {
int pom = *b;
*b = *a;
*a = pom;
}
Tento způsob předávání využijeme taky v případě, že potřebujeme ve funkci pracovat se strukturou. Struktura je obecně kolekce vícero hodnot a může být potenciálně velice velká. Pokud bychom strukturu do funkce předávali hodnotou, zabralo by její zkopírování do parametru poměrně dlouho a program by to tak zdržovalo. My ale můžeme předat pouze odkaz na strukturu a ten má (jak už víme) u Aruino Nano jen 2 byty. A pomocí ukazatelů lze do funkce předávat i pole. O tom ale více v příštím článku 🙂
Dodatek pro zvídavé
Na začátku článku jsme měli funkci, která měla jeden parametru s typem void*.
void prp(void *x);
Co ten „ukazatel na void“ znamená? Je to obecný ukazatel bez určení typu. Funkci je jedno, jaký typ ukazatele dostane. Ukazatel na void se používá jen ve specifických případech a když můžete, tak se mu vyhněte.
Lze pomocí něj ale například vytvořit funkci, která dostane jako první parametr ukazatel typu void* a v druhém parametru jeho datový typ (reprezentovaný předem určeným číslem). Podle typu pak vypíše hodnotu na předaném ukazateli po sériové lince.
void vypis(void *x, byte typ) {
if(typ == 0) {
Serial.println(*(byte *) x);
}
else if(typ == 1) {
Serial.println(*(int *) x);
}
// ...
}
Výraz *(byte *) x si rozebereme zprava. Máme proměnnou x typu void*, tedy obecný ukazatel. Tu pomocí (byte *) přetypujeme na hodnotu typu ukazatel na byte. Na závěr pomocí operátoru * přečteme hodnotu tohoto ukazatele. Přetypování je zde nutné proto, aby kompilátor věděl kolik bytů má z dané adresy přečíst (u byte 1, u int 2 atd.).
Toto je právě část ukazatelů v C, která se trochu může jevit jako magie. Většinou se s ní nesetkáte, ale je dobré vědět, že něco takového existuje. Další výklad si necháme zase na jindy.
Máte nějaké dotazy? Neváhejte se zeptat v komentářích, na Facebooku, nebo třeba na arduino-forum.cz

- Sledovač slunce s Arduinem - 23.3.2022
- Programovatelný kytarový pedál s Arduinem - 26.2.2020
- Arduino infračervený teploměr vytištěný na 3D tiskárně - 11.2.2020
gilhad
21.4.2019 at 12:13Dodatek pro velmi zvidavé:
Ve skutečnosti v C neexistuje předávání hodnot odkazem, pouze se používá iluze, kdy předáváme hodnotou ukazatel na něco a pak to něco jsme schopni změnit, ale ten předávaný ukazatel samozřejmě nikoli.
Arduino ale používá C++, kde už použít předávání hodnot odkazem možno je, ale to se zapisuje jinak
void vymen(int &a, int &b) {
int pom = b;
b = a;
a = pom;
}
….
int a=10;
int b=5;
vymen(a,b);
// a ted a==5 a b==10
viz též
https://stackoverflow.com/questions/2229498/passing-by-reference-in-c
gilhad
20.4.2019 at 3:33Poznámka: Mezeru lze psát před i za hvězdičkou. Zápisy byte* x; a byte *x; jsou ekvivalentní.
Já bych výrazně doporučoval psát hvězdičku ke jménu proměnné, protože to je způsob, jak to chápe překladač – „když dereferencuju x, dostanu byte“. V takto jednoduchém případě to sice vyjde nastejno, ale jakmile začneme dělat cokoli složitějšího, tak narazíme na to, že překladač deklarace louská od jména proměnné zevnitř ven a až na konec skončí u typu.
Prakticky narazíme už i v takto jednoduchém případě:
byte a,b,c; // a je byte, b je byte, c je byte
byte* x,y,z; // x je ukazatel na byte, y je byte (!?!), z je taky byte (!!!)
byte *p, *q, *r; // r je ukazatel na byte, q je ukazatel na byte, r je ukazatel na byte, svět je krásný
byte **d, *e, f; // opět d je ukazatel na ukazatel na byte, e ukazatel na byte, f je byte
mezera místo před, tak za hvězdičkou tuto přehlednost silně naruší:
byte** d,* e, f; // překladači je to jedno, ale kdo to má číst?
Jak číst spletité deklarace je hezky (ale anglicky, ale celkem snadnou angličtinou a s příklady) popsáno například tady:
http://unixwiz.net/techtips/reading-cdecl.html
Zbyšek Voda
20.4.2019 at 18:21Díky za postřeh. Máte samozřejmě pravdu.
Já jsem zvyklý deklarace proměnných rozepisovat na řádky – co proměnná, to jeden řádek. Je to delší, ale dle mě přehlednější. Proto mi tento důsledek nedošel.
Děkuji, doplním to do článku.
gilhad
21.4.2019 at 11:29Děkuji, já také většinou pro přehlednost píšu co deklarace, to řádek, ale i v takovém případě se člověk občas nevyhne deklaraci pole ukazatelů na funkce, kde ten typ prostě vlevo od proměnné zapsat nejde .
Tohle měl logičteji udělané PASCAL, kde se psalo
var
promenna,promenna, promenna: typ;
a ten typ se vypisoval tak, že základní typ (byte, integer, char,…) byl uvnitř
var
a,b,c:byte;
p,q,r: ^byte;// ukazatel na byte
fx: ^array[10..15] of
record
gilhad
21.4.2019 at 11:51oops píšu rychleji než myslím a tab dělá nezdobu, nikoli odsazení …
fx: ^array[10..15] of
record
jmeno:string[10];
fce:^ function (a:byte; b:char): ^ array[‚a‘..’z‘] of ^^ byte;
end;
Takže fx je ukazatel na pole(indexované čísly od 10 do 15, tedy s 6 prvky) záznamů sestávajících z položek jméno (které je řetězec o maximální délce 10 znaků) a fce, což je ukazatel na funkci s parametry a (typu byte) a b (typu znak), která vrací ukazatel na pole indexované znaky ‚a‘ až ‚z‘ obsahující ukazatele na ukazatel na byte
(Jak je vidět, tak tady se to skutečně čte zleva doprava s respektováním (i slovních) závorek (jako ten record .. end)
(přičemž takovéto hrůzy se většinou doporučovalo řešit deklarací vlastních typů, ze kterých se to postupně poskládalo)
pravda je, že pascal vznikl později a byl zaměřen na výuku programování, takže byl víc „ukecaný“ (místo složených závorek {…} se psalo begin … end) , překladač musel odvést víc práce, aby programátor mohl psát hezčí programy. Funkčně tam šlo napsat to samé, ale tlačilo to člověka do hezčího kódu a naopak nebyl takový tlak na to, aby přeložený kód využil každý dostupný byte a takt procesoru.